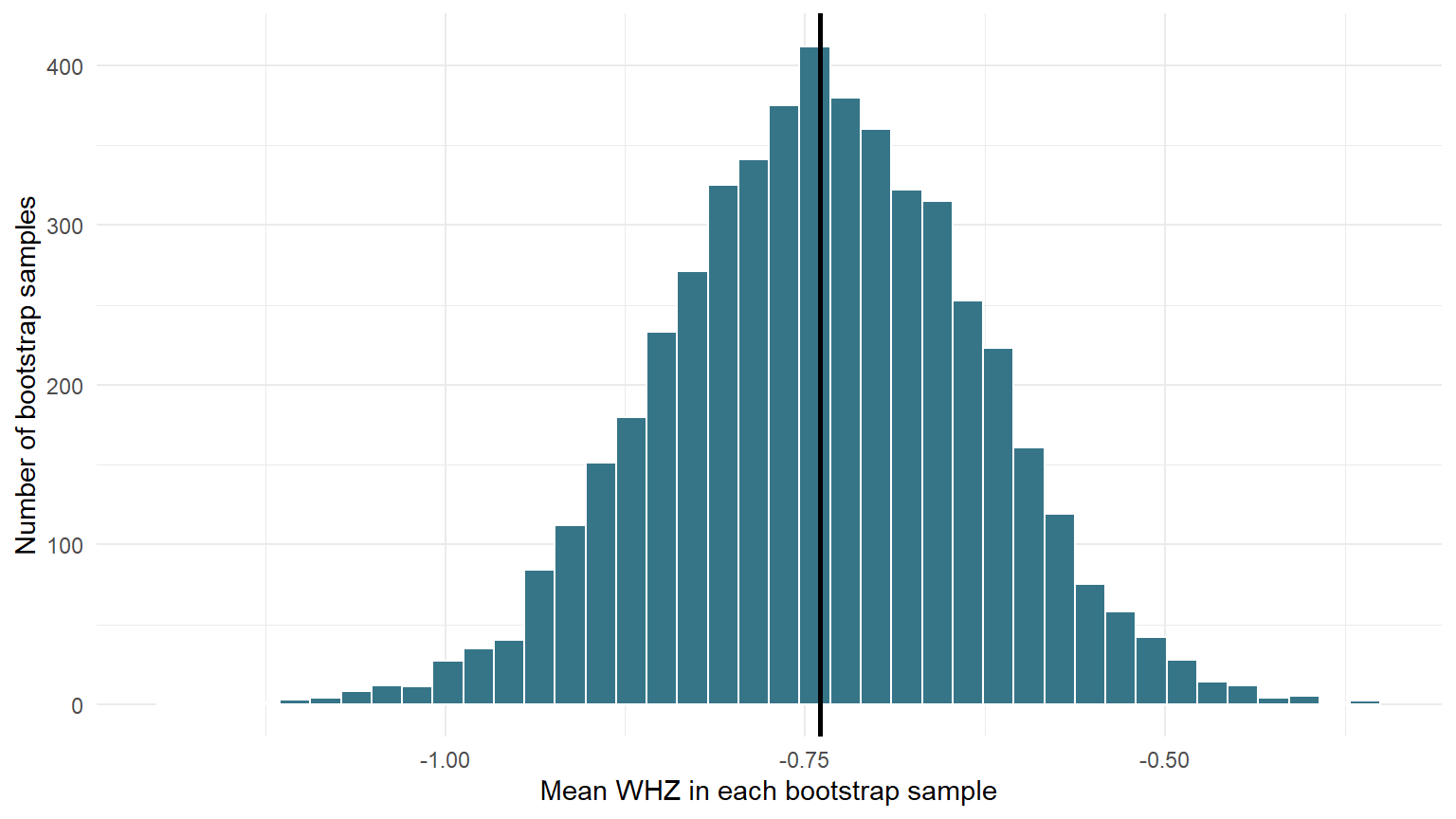Your Supervisor Said ‘Do a Bootstrap’. What Do They Mean?
A practical journey from one sample to bootstrap confidence intervals and hypothesis tests using children’s weight-for-height z-scores.
Published
February 23, 2026
Let us say you are a PhD candidate. You have spent months cleaning your data, fitting your model, and preparing the results. You show the results to your supervisors. One of them looks at your confidence interval and asks:
Did you bootstrap this?
Another one adds:
Carry out a bootstrap and see whether the conclusion remains the same.
You write the comment down. But perhaps you are not completely sure what they have asked you to do. Is bootstrap another statistical test? Is it a way of correcting a bad model? And why does a serious statistical method have the name of something attached to a boot?
The same can happen in a management meeting. A statistician says that the confidence intervals were bootstrapped. If you are not a statistician, you may wonder what this means and whether it changes the decision.
In this article I will use a simple example of children’s weight-for-height z-scores to explain bootstrap. We will first do an ordinary test, then carry out the same test using bootstrap.
Why does it have such a strange name?
Baron Münchhausen was a fictional nobleman famous for telling impossible stories. In one of the stories, he and his horse became trapped in a swamp. He claimed that he escaped by pulling himself and the horse out using his own hair.
The expression “pull yourself up by your own bootstraps” came later. It means doing something that appears impossible without help from outside. In the original story the Baron used his hair, not his bootstraps.
Statistics has a similar problem. We want to know what would happen if we repeated our study many times and collected a new sample each time. Usually, we do not have the money or time to repeat the whole study. We have only one sample.
In bootstrap we use the one sample we have to create many new samples. Bradley Efron formally introduced the statistical method in his 1979 paper, “Bootstrap Methods: Another Look at the Jackknife”. The stories of Baron Münchhausen can also be read through Project Gutenberg.
In simple terms:
A bootstrap repeatedly resamples the data we observed, recalculates the result, and uses the variation in those recalculated results to show how uncertain our original result is.
Let us see what this means using data.
A simple test using weight-for-height z-scores
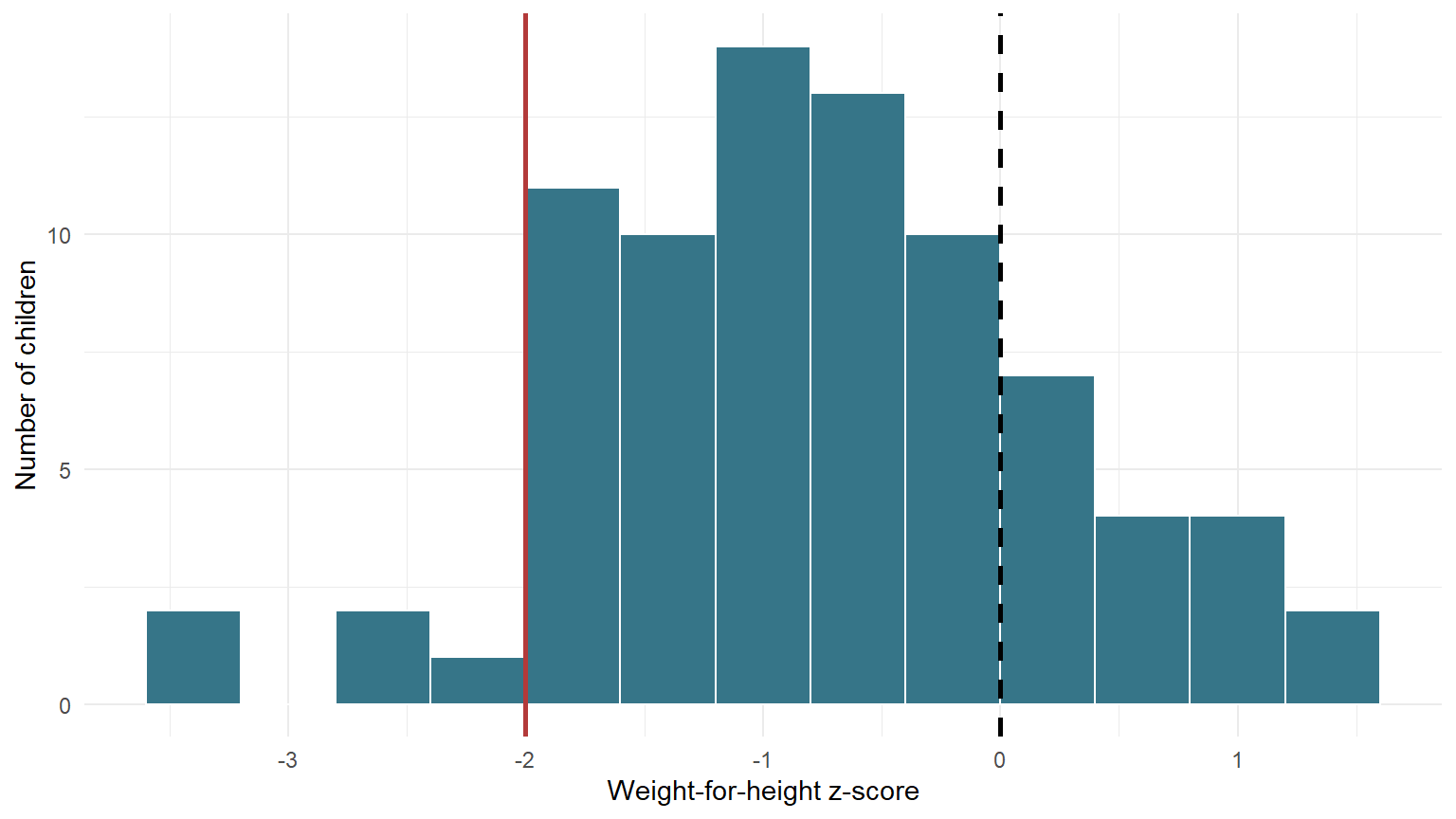
Suppose we collected weight and height measurements from children in a community nutrition survey. We then converted each child’s measurement into a weight-for-height z-score, which we will call WHZ.
The null hypothesis says that the population mean WHZ is at the reference median. The alternative says it is below the reference median.
This is not yet a test of how many children are wasted. A mean below 0 and an individual WHZ below -2 are different things. We will return to that distinction.
The p-value is 1.77^{-9}. If the population mean were really 0, a sample result this far below 0 would be unusual under the assumptions of the t-test.
The t-test compares our observed mean with what we would expect if the population mean were zero. It does this using a t-distribution. We now want to see whether bootstrap gives us the same conclusion.
We start with one bootstrap sample before repeating the process 5,000 times.
Taking one bootstrap sample
For a small demonstration, take the first 10 WHZ values.
We sampled 10 values from the original 10 values with replacement. After drawing a value, we put it back before drawing again. This is why one value can appear several times while another value may not appear at all.
The original mean of these 10 values is -1.26. The mean of this particular resample is -1.04.
One resample does not tell us much. The next step is to repeat the process many times.
Repeating the sample 5,000 times
We now resample all 80 children 5,000 times. Each time, we calculate the mean WHZ.
Bootstrap distribution of 5,000 sample means. The solid line is the observed sample mean.
This graph is called the bootstrap distribution of the mean. It shows how the mean changes when the observed sample is resampled again and again.
The standard deviation of these 5,000 means is 0.109. We call this the bootstrap standard error. It is an estimate of the typical sampling variation in the mean.
The middle 95% of the bootstrap means run from -0.95 to -0.53. The interval is entirely below zero. In practical language, the data suggest that the population represented by this sample has a mean WHZ below the WHO reference median.
Notice what we have done so far. We resampled the observations without changing them first. This is useful for estimating the uncertainty around the observed mean. It is not yet a valid bootstrap hypothesis test.
Preparing the data for a hypothesis test
Our observed data have a negative mean. When we resample them as they are, the bootstrap samples will also tend to have a negative mean. That is exactly what we want when building a confidence interval around the observed result.
For hypothesis testing we need to ask a different question:
What kind of test statistics would we observe if the null hypothesis were true?
The null hypothesis says that the population mean is 0. We therefore create a world where this is true by shifting every observed value by the same amount:
\[
x_i^{0} = x_i - \bar{x} + \mu_0,
\]
where \(\bar{x}\) is the observed mean and \(\mu_0\) is the value specified by the null hypothesis. Here, \(\mu_0 = 0\).
This transformation keeps the shape and spread of the observed values, but moves their mean to zero.
The centre has moved to zero, but the standard deviation has not changed. We can now resample from these recentered values to see what results the null world produces.
Carrying out the bootstrap hypothesis test
We will use the same statistic as the ordinary t-test:
This is called a studentized statistic because the difference in means is scaled by its estimated standard error. A large negative value provides evidence for our alternative hypothesis that \(\mu < 0\).
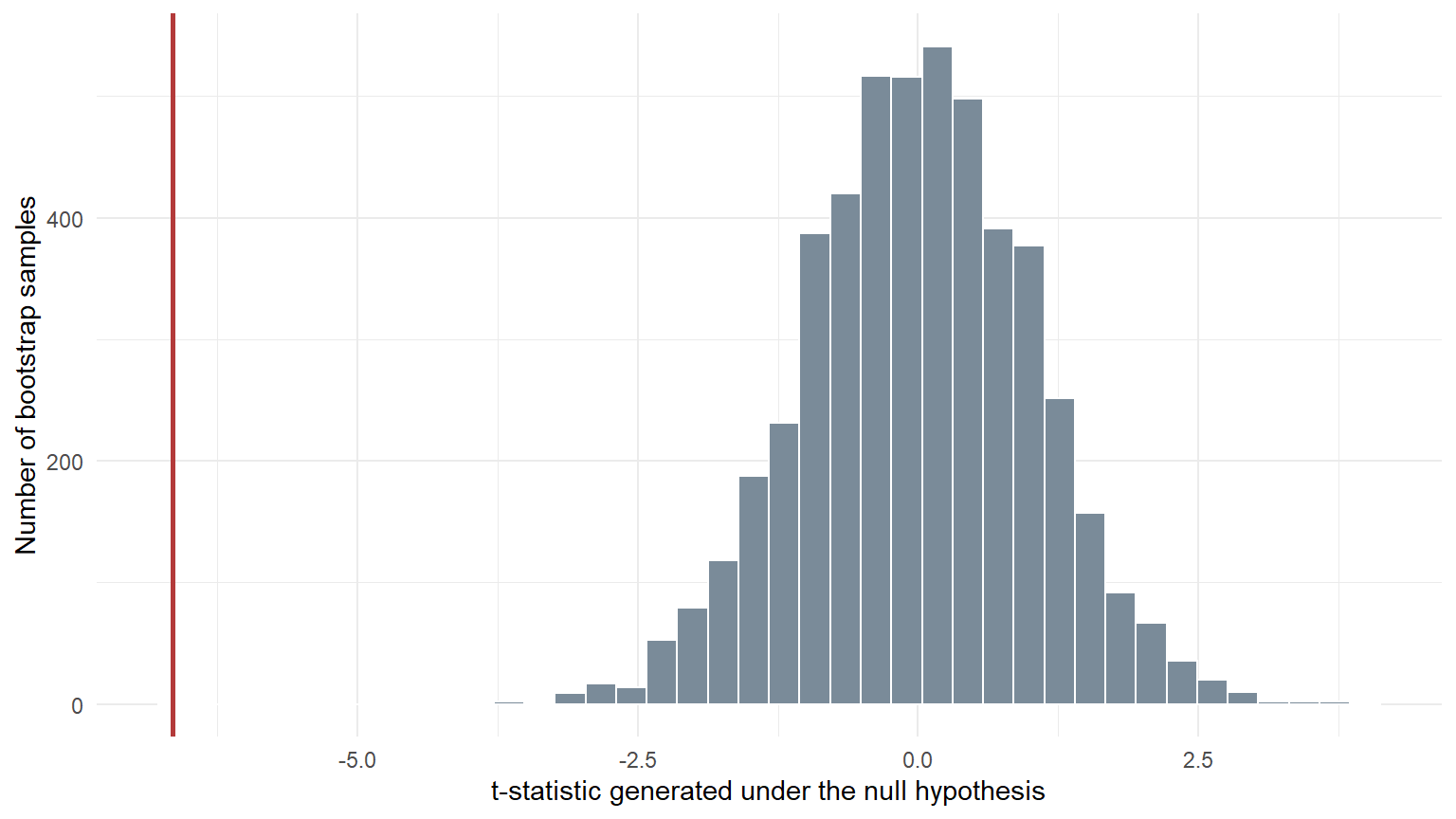
Bootstrap null distribution of the t-statistic. The red line is the statistic observed in the original sample.
The observed t-statistic is -6.64. The bootstrap p-value is 2^{-4}.
The p-value is the proportion of bootstrap samples generated under the null hypothesis that produced a t-statistic at least as negative as the one we observed. We use the small Monte Carlo correction:
The 1 in the numerator and denominator prevents us from reporting a p-value of exactly zero merely because a finite simulation did not produce a more extreme result.
The two p-values do not have to be identical. The classical test uses the t-distribution as its null reference. The bootstrap test estimates the null distribution by resampling the recentered data.
What matters here is the substantive conclusion. Both methods indicate that the negative sample mean would be difficult to explain if the population mean WHZ were really zero.
Mean WHZ is not the prevalence of wasting
No. This is an important distinction.
Our mean analysis asked whether children are below the WHO reference median on average. Wasting is an individual classification. According to the WHO definition, a child is wasted when WHZ is below -2.
If a manager asks, “What percentage of children are wasted?”, the statistic we need is:
\[
\widehat{\pi}
=
\frac{
\text{number of children with WHZ below } -2
}{
\text{number of children measured}
}.
\]
We can bootstrap this proportion in the same way we bootstrapped the mean: resample children, calculate the proportion wasted, and repeat.
The estimated prevalence of wasting is 6.2%. The bootstrap interval runs from 1.2% to 12.5%.
For a manager, the interval is often more useful than the point estimate alone. Another sample from the same population would not necessarily produce exactly 6.2%. The interval shows a plausible range of sampling uncertainty.
There is an additional warning. If the children came from a complex survey with villages as clusters, strata, or unequal sampling weights, resampling individual children as though they were independently selected may be wrong. The bootstrap must respect the way the sample was collected.
The mathematics behind bootstrap
Let us now write the same idea using statistical notation. Suppose the population follows an unknown distribution \(F\). The quantity we want to estimate is:
\[
\theta = t(F).
\]
The function \(t(F)\) can represent a population mean, median, prevalence, or regression coefficient. We observe a sample:
\[
X_1, X_2, \ldots, X_n \sim F,
\]
but we do not know \(F\). Bootstrap replaces \(F\) with the empirical distribution of the values in our sample:
This gives each observed value a probability of \(1/n\). Sampling from \(\widehat{F}_n\) is therefore the same as sampling the observed values with replacement.
The collection of values \(\widehat{\theta}^{*(1)}, \ldots,
\widehat{\theta}^{*(B)}\) is the bootstrap distribution. Its spread tells us how much the statistic changes from one bootstrap sample to another.
For a percentile confidence interval we take the lower and upper percentiles:
For a 95% interval, these are the 2.5th and 97.5th percentiles. This is the method we used for the mean WHZ and wasting prevalence. Other methods, such as the bootstrap-t and bias-corrected and accelerated intervals, may be more appropriate when the bootstrap distribution is highly skewed or biased.
Nonparametric and parametric bootstrap
So far, we have used the nonparametric bootstrap. It resamples the observed values. There is another common approach.
bootstrap_methods <-data.table(Method =c("Nonparametric bootstrap", "Parametric bootstrap"),`What creates a new dataset?`=c("Resampling the observed data","Simulation from a fitted probability model" ),`Main assumption`=c("The sample represents the population and the resampling scheme matches the design","The fitted model reasonably describes how the data arise" ),`Question to ask`=c("What exactly was resampled?","What model generated the simulated data?" ))kable(bootstrap_methods)
Method
What creates a new dataset?
Main assumption
Question to ask
Nonparametric bootstrap
Resampling the observed data
The sample represents the population and the resampling scheme matches the design
What exactly was resampled?
Parametric bootstrap
Simulation from a fitted probability model
The fitted model reasonably describes how the data arise
What model generated the simulated data?
For our WHZ data, a parametric bootstrap could assume a Normal distribution, estimate its mean and standard deviation, and simulate new values from that fitted distribution. For hypothesis testing, we would simulate under the null:
This is convenient, but it adds a stronger assumption: that the Normal model is a good description of the WHZ values.
Testing a model coefficient using the crab data
So far we have tested a sample mean. We can use the same bootstrap idea when the hypothesis concerns a regression coefficient.
Let us use the crabs dataset in the MASS package. It contains measurements from 200 crabs of two species. We will use sp, the crab species; CW, the carapace width; and sex, whether the crab is female or male.
Suppose our question is:
After accounting for carapace width, does sex help us distinguish the two crab species?
We fit a logistic regression because the outcome has two categories. The full model is:
A large value means that the full model improves substantially on the reduced model. The ordinary test compares this statistic with a chi-square reference distribution.
Simulating crab data under the null hypothesis
For the WHZ test, we recentered the values so their mean was zero. Here the reduced model already represents the null hypothesis. It says that species probability depends on width but not on sex.
We therefore take the probabilities fitted by the reduced model and use them to simulate a new species outcome for every crab. We then fit both models to the simulated data and recalculate the likelihood-ratio statistic.
The observed likelihood-ratio statistic is 0.0529. The classical p-value is 0.8181 and the bootstrap p-value is 0.8168. The two p-values are almost the same and both are large. We therefore do not have evidence that adding sex improves the model after accounting for carapace width.
This follows the same procedure as the WHZ test. We state the null hypothesis, generate data under that hypothesis, recalculate the statistic, and find out how often the simulated statistic is at least as large as the observed one.
This is a parametric bootstrap because the new species outcomes are generated from the reduced logistic model. The result therefore depends on that model being a reasonable description of the data under the null hypothesis.
What bootstrap cannot rescue
Bootstrap is useful, but it is not magic.
It cannot correct a sample that systematically excluded important people.
It cannot turn 15 observations into the information contained in 15,000 independent observations.
It cannot ignore clustering, repeated measurements, survey weights, or time order.
It cannot make a badly specified parametric model correct.
It cannot recover population patterns that are absent from the observed sample.
Resampling a problem 5,000 times gives you 5,000 versions of the same problem.
For independent observations, resampling rows may be reasonable. For a clustered survey, we may need to resample clusters. For longitudinal data, we may need to resample people or blocks of time. For a regression, we must decide whether to resample rows, residuals, clusters, or simulate from a fitted model.
The difficult part of bootstrap is often not writing the loop. It is deciding what represents a valid repeat of the study.
What should you ask when somebody says they bootstrapped the result?
If you are the PhD candidate, ask:
What statistic am I bootstrapping?
What exactly should be resampled?
Does that resampling respect how the data were collected?
For a hypothesis test, how did I make the null hypothesis true?
Did the bootstrap and conventional analysis tell the same practical story?
Would more bootstrap repetitions materially change the result?
If you are the manager listening to a presentation, ask:
What uncertainty does this interval describe?
Does the sample represent the people about whom we want to make a decision?
What assumptions were made when generating the bootstrap samples?
Would our decision change near the lower or upper end of the interval?
The next time a supervisor or statistician asks whether you bootstrapped the result, you do not need to hear it as an incantation. They are asking how stable your conclusion is when the observed data are made to play the role of many possible samples.
Your next question should be:
What did we resample, and did we resample it in a way that respects how the data were collected?