Sampling is an important technique in your statistical arsenal. It isn’t always appropriate though—you need to know when to use it and when to work with the whole dataset.
Which of the following is not a good scenario to use sampling?
when data set is small
Simple sampling with dplyr
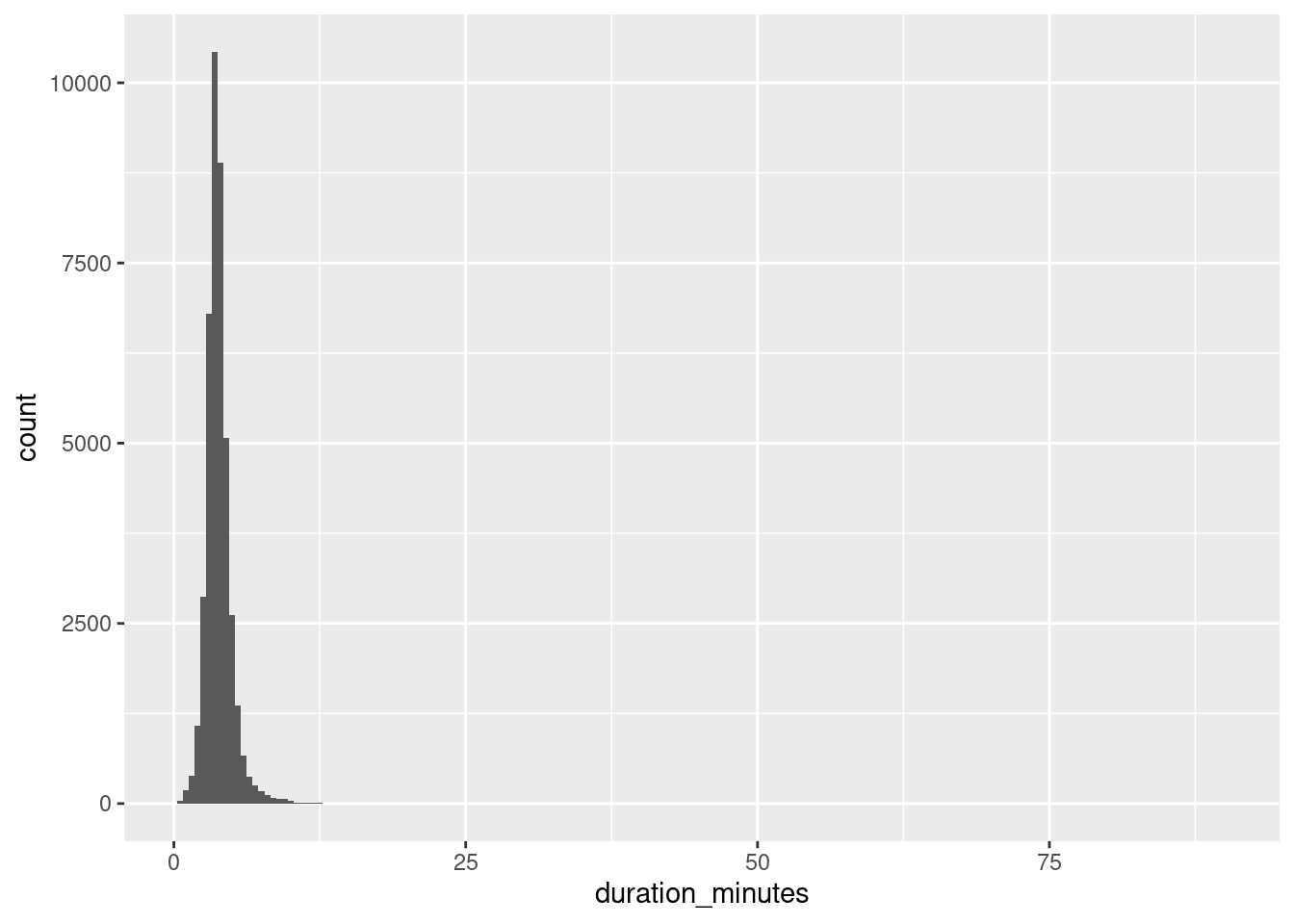
Throughout this chapter you’ll be exploring song data from Spotify. Each row of the dataset represents a song, and there are 41656 rows. Columns include the name of the song, the artists who performed it, the release year, and attributes of the song like its duration, tempo, and danceability. We’ll start by looking at the durations.
Your first task is to sample the song dataset and compare a calculation on the whole population and on a sample.
spotify_population is available and dplyr is loaded.
library(tidyverse)library(fst)library(knitr)spotify_population <-read_fst("data/spotify_2000_2020.fst")# View the whole population dataset# Sample 1000 rows from spotify_populationspotify_sample <-slice_sample(spotify_population, n =10)# See the resultkable(spotify_sample)
acousticness
artists
danceability
duration_ms
duration_minutes
energy
explicit
id
instrumentalness
key
liveness
loudness
mode
name
popularity
release_date
speechiness
tempo
valence
year
0.17100
[‘John K’]
0.958
144427
2.407117
0.376
0
5HBDBBr5OV90lubqW8ctJF
0.000000
8
0.1270
-7.063
1
if we never met
76
2019-04-26
0.0523
107.964
0.331
2019
0.20400
[‘The Chainsmokers’, ‘Bebe Rexha’]
0.585
217640
3.627333
0.696
0
2oejEp50ZzPuQTQ6v54Evp
0.000000
4
0.3440
-5.600
0
Call You Mine
83
2019-12-06
0.0307
104.010
0.522
2019
0.38800
[‘Never Shout Never’]
0.768
178144
2.969067
0.683
0
2waLDWGLc4Q14ZVyDNrxLM
0.000000
7
0.2860
-7.173
1
cheatercheaterbestfriendeater
57
2010-08-23
0.0604
99.955
0.669
2010
0.57200
[‘Conway Twitty’]
0.638
199600
3.326667
0.377
0
4VF5XIZ7EiMfLElRzYG2E8
0.000000
2
0.1020
-15.640
1
I’d Love To Lay You Down
52
2001-01-01
0.0341
81.911
0.778
2001
0.00879
[‘Los Angeles Azules’, ‘Jay de la Cueva’]
0.526
336147
5.602450
0.765
0
6rEA2GbBkGC9GqOOrBwvza
0.000463
0
0.9670
-4.544
1
17 Años - Concierto Sinfónico Cumbia Fuzion
51
2015-10-16
0.0368
91.035
0.627
2015
0.00575
[‘Modest Mouse’]
0.521
229867
3.831117
0.931
0
72zsr1jSMnaMPtl713jXeJ
0.000000
2
0.2430
-4.549
1
Bury Me With It
44
2004-04-05
0.0654
170.048
0.816
2004
0.99400
[‘Mae Ji-Yoon’]
0.671
173719
2.895317
0.200
0
1COWV6U3LKqCBpiHPthbiB
0.939000
8
0.1140
-23.978
1
Vibrations
65
2017-09-10
0.0365
107.517
0.530
2017
0.13200
[‘Dr. Dog’]
0.454
234800
3.913333
0.820
0
0UV5zxRMz6AO4ZwUOZNIKI
0.000969
2
0.1150
-4.193
1
Where’d All the Time Go?
65
2010-11-02
0.0567
166.303
0.575
2010
0.03890
[‘Lil Baby’]
0.902
162791
2.713183
0.850
1
2XEsbmynS9dLSzNSuZzfXF
0.000000
7
0.0838
-6.390
1
Same Thing
64
2020-02-28
0.3580
120.132
0.556
2020
0.68400
[‘invention_’]
0.543
184000
3.066667
0.467
0
00DTeE4nekCTgYz1QYHXSl
0.006040
4
0.3510
-11.223
1
Nature Bump 000
54
2015-06-06
0.2740
75.293
0.328
2015
Simple sampling with dplyr
Throughout this chapter you’ll be exploring song data from Spotify. Each row of the dataset represents a song, and there are 41656 rows. Columns include the name of the song, the artists who performed it, the release year, and attributes of the song like its duration, tempo, and danceability. We’ll start by looking at the durations.
Your first task is to sample the song dataset and compare a calculation on the whole population and on a sample.
spotify_population is available and dplyr is loaded.
# Calculate the mean duration in mins from spotify_populationmean_dur_pop <-summarize(spotify_population, mean(duration_minutes))# Calculate the mean duration in mins from spotify_samplemean_dur_samp <-summarize(spotify_sample, mean(duration_minutes))# See the resultsmean_dur_pop
mean(duration_minutes)
1 3.852152
mean_dur_samp
mean(duration_minutes)
1 3.435225
Simple sampling with base-R
While dplyr provides great tools for sampling data frames, if you want to work with vectors you can use base-R.
Let’s turn it up to eleven and look at the loudness property of each song.
spotify_population is available.
# From previous steploudness_pop <- spotify_population$loudnessloudness_samp <-sample(loudness_pop, size =100)# Calculate the standard deviation of loudness_popsd_loudness_pop <-sd(loudness_pop)# Calculate the standard deviation of loudness_sampsd_loudness_samp <-sd(loudness_samp)# See the resultssd_loudness_pop
[1] 4.524076
sd_loudness_samp
[1] 4.184483
Are findings from the sample generalizable?
You just saw how convenience sampling—collecting data via the easiest method can result in samples that aren’t representative of the whole population. Equivalently, this means findings from the sample are not generalizable to the whole population. Visualizing the distributions of the population and the sample can help determine whether or not the sample is representative of the population.
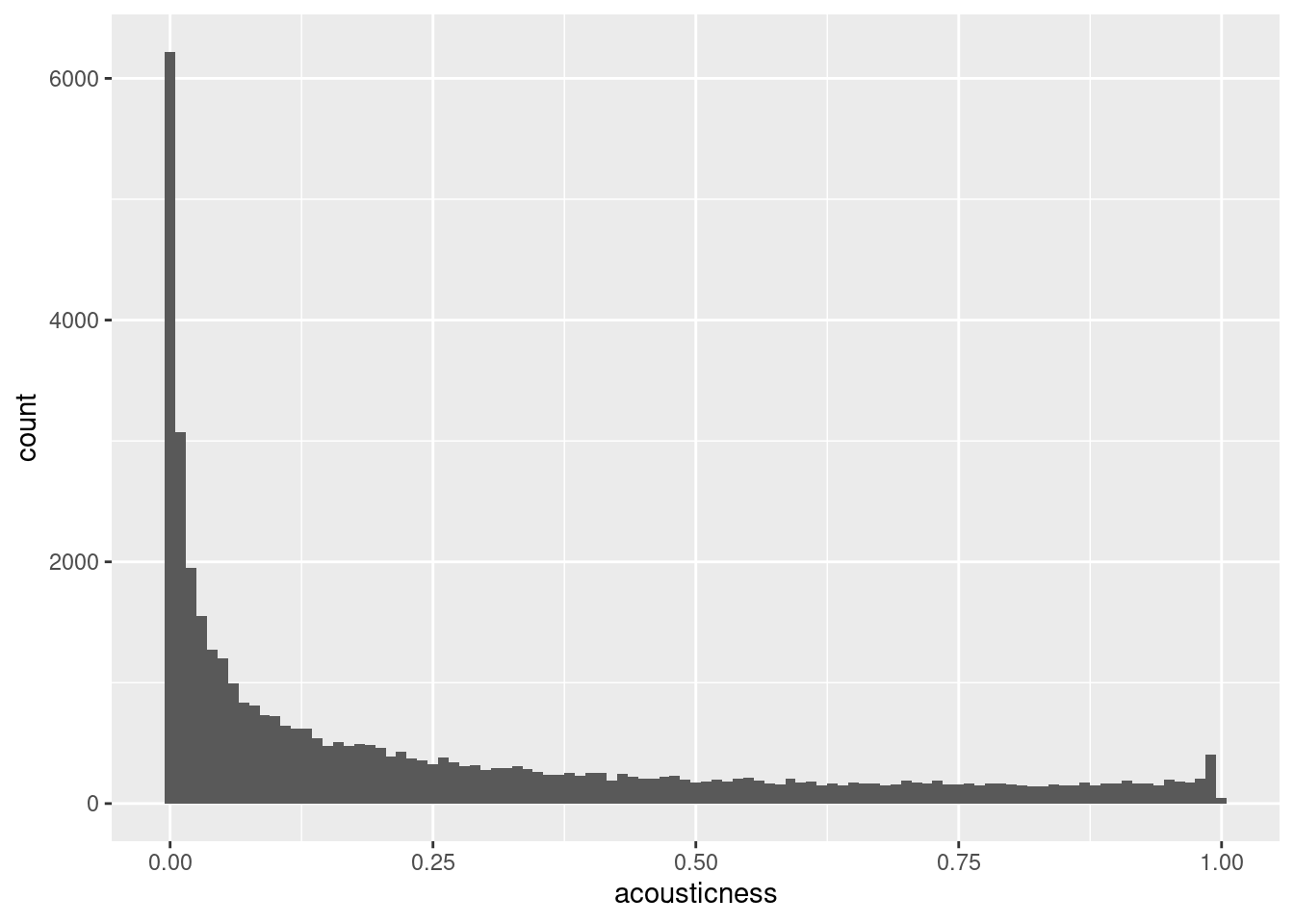
The Spotify dataset contains a column named acousticness, which is a confidence measure from zero to one of whether the track is acoustic, that is, it was made with instruments that aren’t plugged in. Here, you’ll look at acousticness in the total population of songs, and in a sample of those songs.
spotify_population and spotify_mysterious_sample are available; dplyr and ggplot2 are loaded.
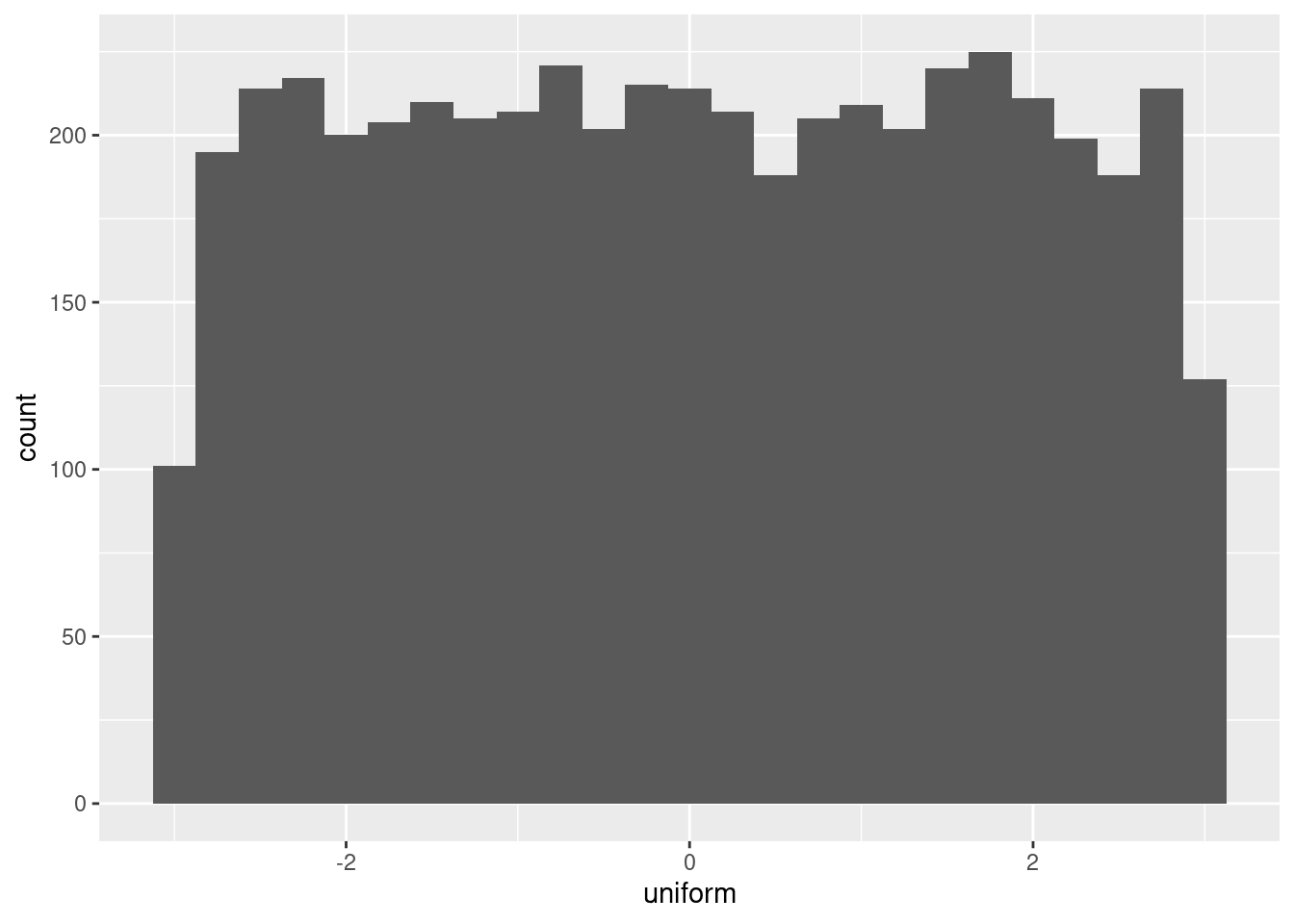
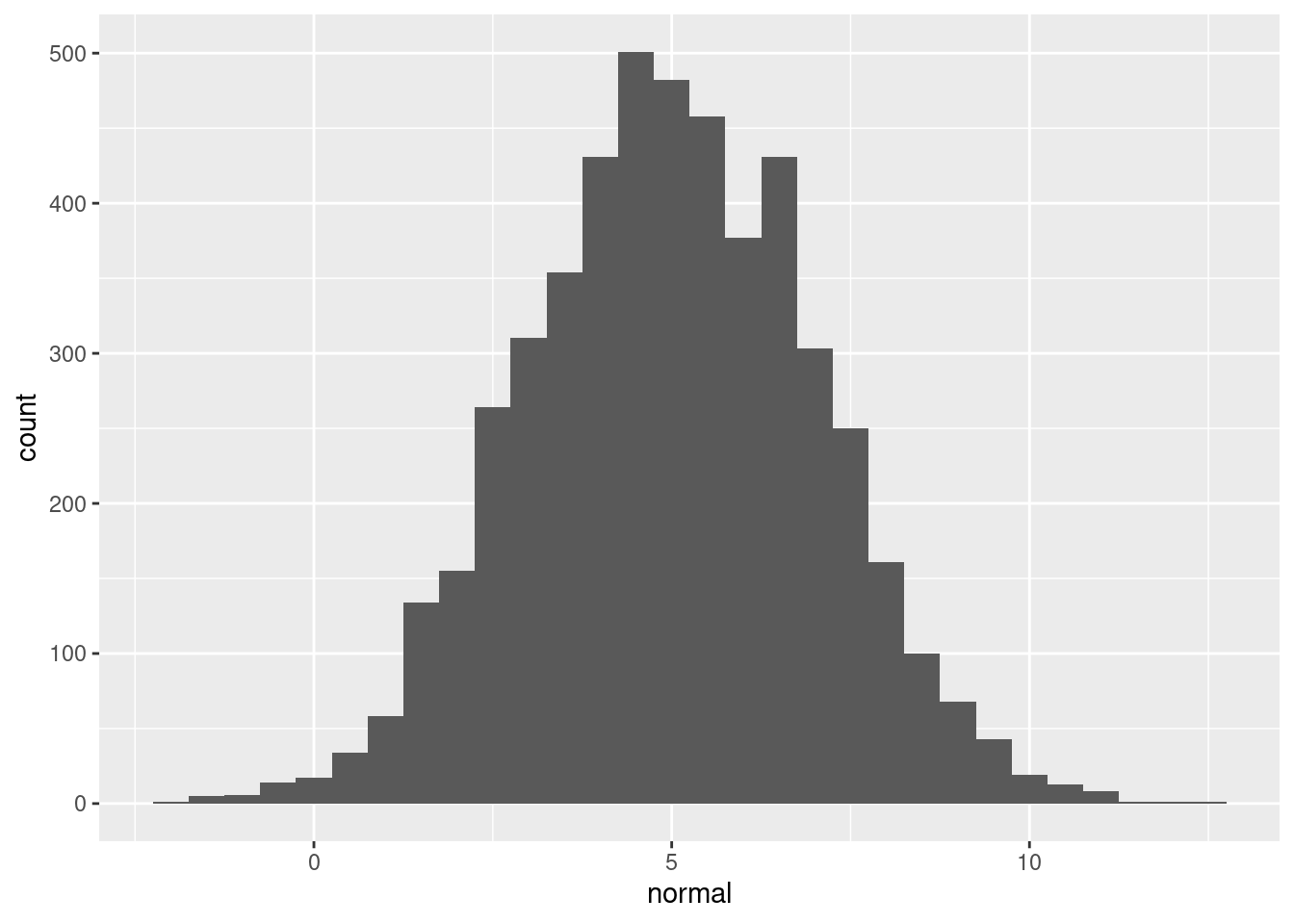
You’ve seen sample() and it’s dplyr cousin, slice_sample() for generating pseudo-random numbers from a set of values. A related task is to generate random numbers that follow a statistical distribution, like the uniform distribution or the normal distribution.
Each random number generation function has a name beginning with “r”. It’s first argument is the number of numbers to generate, but other arguments are distribution-specific. Free hint: Try args(runif) and args(rnorm) to see what arguments you need to pass to those functions.
n_numbers is available and set to 5000; ggplot2 is loaded.
n_numbers <-5000# Generate random numbers from ...randoms <-data.frame(# a uniform distribution from -3 to 3uniform =runif(n_numbers, -3, 3),# a normal distribution with mean 5 and sd 2normal =rnorm(n_numbers, mean =5, sd =2))# Plot a histogram of uniform values, binwidth 0.25ggplot(randoms, aes(uniform)) +geom_histogram(binwidth =0.25)
# Plot a histogram of normal values, binwidth 0.5ggplot(randoms, aes(normal)) +geom_histogram(binwidth =0.5)
Understanding random seeds
While random numbers are important for many analyses, they create a problem: the results you get can vary slightly. This can cause awkward conversations with your boss when your script for calculating the sales forecast gives different answers each time.
Setting the seed to R’s random number generator helps avoid such problems by making the random number generation reproducible. - The values of x are different to those of y.